
일단 씻고 나가자
[스프링 부트 핵심 가이드] 08. Spring Data JPA 활용 본문
(본 포스팅은 해당 도서의 정리 및 개인 공부의 목적 포스팅임을 밝힙니다.)
장정우, 『스프링 부트 핵심 가이드 : 스프링 부트를 활용한 애플리케이션 개발 실무』, 위키북스, 2022
08. Spring Data JPA 활용
Spring Data JPA에서 제공하는 기능들을 알아보고, 리포지토리 클래스에서 활용법을 실습해보자.
8.1 프로젝트 생성
이번 장의 실습을 위해 새로운 프로젝트를 생성한다.
이전과 동일하게 start.spring.io 에 접속하여 다음 사진과 같이 설정 후, 압축을 해제하고 인텔리제이로 open한다.

프로젝트를 open 했다면, 6장에서 작성한 일부 코드를 가져와야 한다.
다음 사진에 있는 패키지 및 파일의 목록을 해당 위치에 복사 붙여넣기 한다.

이때 클래스들 뿐 아니라 resorces의 application.properties의 내용과 logback-spring.xml 파일도 동일하게 가져온다.
단순히 클래스를 복사 - 붙여넣기 한다면 기존 파일에 설정되어 있는 import의 경로가 새로운 프로젝트와 맞지 않으므로,
기존 import 부를 지우고 해당 패키지에 맞는 새로운 경로로 import 해주어야 한다.
즉, 파일(클래스)을 하나하나 들어가서 return 타입 혹은 레퍼런스 타입이 빨간 글씨로 에러를 띄우고 있는지 확인하고,
만약 그렇다면 해당 클래스의 import 부를 지우고 새롭게 import 하는 작업을 진행해야 한다.
이후 AdvancedJpaApplication에서 서버를 실행해보고 정상적으로 동작하는지 확인하는 것으로 설정을 마친다.
8.2 JPQL
JPA Query Language의 준말로, JPA에서 사용할 수 있는 쿼리를 뜻한다.
SQL문과 유사하며, SQL과의 차이점은 대상이 테이블 혹은 컬럼이 아니라 엔티티 객체 혹은 필드인 것 뿐이다.
(ex. SELECT p FROM Product p WHERE p.number = ?1 ;)
8.3 쿼리 메서드 살펴보기
앞서 우리는 JpaRepository 인터페이스를 상속 받는 것만으로도 save 등의 CRUD 관련 유용한 함수를 활용할 수 있었다.
하지만 제공하는 기본 메서드들은 식별자 기반 생성으로, 식별자가 아닌 다른 데이터 기준의 sql 문에서는 한계가 있다.
기본적으로 제공하지 않는 식별자가 아닌 데이터를 기준으로 한 메서드를 사용하고자 할 때 활용할 수 있는 것이 쿼리 메서드이며, 쿼리 메서드는 JpaRepository를 상속받은 우리의 Repository 인터페이스에 함수명을 규칙에 맞게 선언하는 것만으로도 내용을 구현하지 않아도 해당 메서드로 원하는 기능을 사용할 수 있다.
이번 장에서는 이런 쿼리 메서드를 사용하는 방법을 알아보자.
8.3.1 쿼리 메서드의 생성
쿼리 메서드는 크게 동작을 결정하는 주제(Subject)와 서술어(Predicate)로 구분한다.
findById 함수를 예를 들면, 동작의 주제(사용하고자 하는 기능 - CRUD)는 find이며, 기능의 대상이 되는 서술어는 Id이다.
이렇게 주제와 서술어의 조합으로 조건을 명시하는 함수명을 붙이는 것이 쿼리 메서드의 생성 규칙이며, 서술어는 OR 혹은 AND로 조건의 확장 또한 가능하다.
당연하게도 서술어에 들어가는 대상(속성)은 엔티티에서 관리하는 필드만이 가능하다.
8.3.2 쿼리 메서드의 주제 키워드
우선 주제(Subject)에 사용할 수 있는 주요 키워드를 알아보자.
| 기능 | 함수명 | return 타입 | 예시 |
| 조회 | find... | - Optional - 엔티티 객체 - Collection/ stream의 하위 타입 |
Porduct findByName(String name); |
| read... | Optional<Product> readByName(String name); | ||
| get... | Product getByName(String name); | ||
| qeury... | Product queryByName(String name); | ||
| search... | Product searchByName(String name); | ||
| stream... | Stream<Product> streamByName(String name); | ||
| 존재 여부 확인 | exists... | boolean | boolean existsByName(String name); |
| 조회 결과 레코드 개수 | count... | long | long countByName(String name); |
| 삭제 | delete... | void | void deleteByName(String name); |
| remove... | long (삭제 횟수) | long removeByName(String name); | |
| 조회 결과 레코드 전체 | ...All... | List<엔티티> | List<Product> findAllByName(String name); |
| 조회 결과 레코드 개수만큼 (단건일 땐 숫자 제거) | ...Top<number>... | List<엔티티> | List<Product> findTop10ByName(String name); |
| ...First<number>... | List<엔티티> | List<Product> findFirst10ByName(String name); |
함수의 가장 앞단에 사용할 수 있는 주제의 주요 키워드이다.
뒤의 '...' 부분에는 도메인(엔티티) 명을 명시할 수 있는데, 어차피 리포지토리에서 도메인을 명시하기 때문에 중복으로 판단하여 생략하기도 한다.
8.3.3 쿼리 메서드의 조건자 키워드
이어서 서술어(Predicate)에서 사용할 수 있는 주요 키워드를 알아보자.
| 기능 | 비고 | 함수명 | 예시 |
| 일치 | 주로 생략 | ...Is | Product findByNameIs(String name); |
| ...Equals | Product findByNameEquals(String name); | ||
| 불일치 | Is를 생략하고 Not만 사용 가능 | ...(Is)Not | Product findByNameIsNot(String name); |
| null 검사 | 일치, 불일치 키워드와 조합 가능 |
...Null | List<Product> findByNameNull(String name); |
| List<Product> findByNameIsNotNull(String name); | |||
| boolean 타입 칼럼 값 확인 |
boolean으로 지정된 칼럼만을 명시 하여야 함 |
...(Is)True | Product findByIsFoodTrue(); |
| ...(Is)False | Product findByIsFoodIsFalse(); | ||
| 조건 연계 | 여러 조건의 나열에서 활용 | ...And... | Product findByNameAndPrice(String name, long price); |
| ...Or... | Product findByNameOrPrice(String name, long price); | ||
| 비교 연산 | - 숫자, datetime 칼럼만을 대상으로 하여야 함 - 경곗값이 포함되지 않음 (초과, 미만만 확인) 경곗값을 포함하려면 Equal 사용 |
(Is)GreaterThan | List<Product> findByPriceGreaterThan(long price); |
| (Is)LessThan | List<Product> findByPriceLessThanEqual(long price); | ||
| (Is)Between | List<Product> findByPriceBetween(long low, long high); | ||
| 일부 일치 | - SQL문의 '%'와 같은 기능 - Start,End,Contain의 뒤에 'ing'는 's'로 교환 가능. (ex. StartsWith) |
||
| 문자열의 앞 | (Is)StartingWith | List<Product> findByNameStartingWith(String name); | |
| 문자열의 끝 | (Is)EndingWith | List<Product> findByNameIsEndingWith(String name); | |
| 문자열의 양 끝 | (Is)Containing | List<Product> findByNameContainsWith(String name); | |
| 코드 수준에서 메서드를 호출하며 전달하는 값에 '%'를 명시적으로 입력해야 함. |
(Is)Like | List<Product> findByNameIsLike(String name); |
(+) 실습
앞서 살펴본 쿼리 메서드가 제대로 동작하는지 확인해보자.
실습을 통해 알아보기 위하여, 위에서 만든 프로젝트에 swagger와 database 정보를 추가해주어야 한다.
6장 프로젝트의 config 프로젝트와 하위의 SwaggerConfiguration 클래스, 그리고 해당 클래스의 api() 함수 내부의 basePackage 경로를 현재 프로젝트로 바꾸어주고,
pom.xml 파일에 springfox dependency를 추가, parent의 spring framework 버전을 바꾸어준다. (6장 참고)
이전 6장의 프로젝트에서 application.properties 내용을 그대로 복사했기 때문에, 데이터베이스에 대한 별도의 설정은 필요하지 않다.
설정을 마치면 서버를 실행하고 swagger에 접속하여 페이지가 잘 뜨는지 확인하고, 실습을 진행하자.
우선 실습 이전에, 해당 실습은 책에서 나오지 않은 필자가 임의로 테스트하기 위한 코드이므로 절대로 정상적인 코드가 아니다. 절대로 해당 방식으로 그대로 스프링을 사용하지 않길 권고한다.
실습의 진행 방향은 이렇다.
- JpaRepository를 상속받은 ProductRepository에 앞서 살펴본 규칙대로 함수를 선언한다.
- controller 패키지에 새로운 클래스를 만든다. 이 클래스는 간단히 요청을 Get으로 받아 요청에 대한 정보를 콘솔창에만 띄운다.
- 기존의 ProductController로 데이터를 POST 한다.
- 데이터베이스에서 해당 데이터를 확인하고, url을 통해 요청하고 결과를 확인한다.
우선 ProductRepository에 위에서 살펴본 규칙에 맞는 함수를 선언해준다. 간단한 테스트를 위해 다음과 같이 메서드들을 선언했다.

이후 controller에 실습만을 위한 클래스를 만든다. 해당 클래스의 실습 메서드들은 편의를 위해 ProductRepository를 바로 Autowired했다. 다시 한번 언급하지만 이러한 방식으로 레이어의 단계를 건너뛰어 바로 사용하는 방법은 권장되지 않으며, 스프링의 의도와 맞지 않는다. 간단한 실습용으로만 확인하길 바란다.
해당 클래스의 내용은 다음과 같다. 우리는 이전에 만들어두었던 ProductController를 통해 데이터를 넣고, 해당 클래스로 응답을 확인할 것이다. 응답은 콘솔창에 출력된다.

package com.springboot.advanced_jpa.controller;
import com.springboot.advanced_jpa.data.entity.Product;
import com.springboot.advanced_jpa.data.repository.ProductRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.util.List;
@RestController
@RequestMapping("/practice")
public class JpaPracticeController {
private final ProductRepository productRepository;
@Autowired
public JpaPracticeController(ProductRepository productRepository){
this.productRepository = productRepository;
}
@GetMapping("/getOne/{param}")
public void getOne(@RequestParam String param){
Product product = productRepository.findByName(param);
System.out.println("findByName --> " + param);
System.out.println(product.toString());
}
@GetMapping("/getList/{param}")
public void getList(@RequestParam String param){
List<Product> list = productRepository.findAllByName(param);
System.out.println("findAllByName --> " + param);
System.out.println("== List start!! ==");
for(Product p : list){
System.out.println(p.toString());
}
System.out.println("== List end!! ==");
long count = productRepository.countByName(param);
System.out.println("countByName --> " + count);
}
}
클래스 설정까지 마쳤다면 서버를 실행하고 swagger에 접속한다.
다음과 같이 우리가 만들었던 클래스도 잘 나오고 있다.
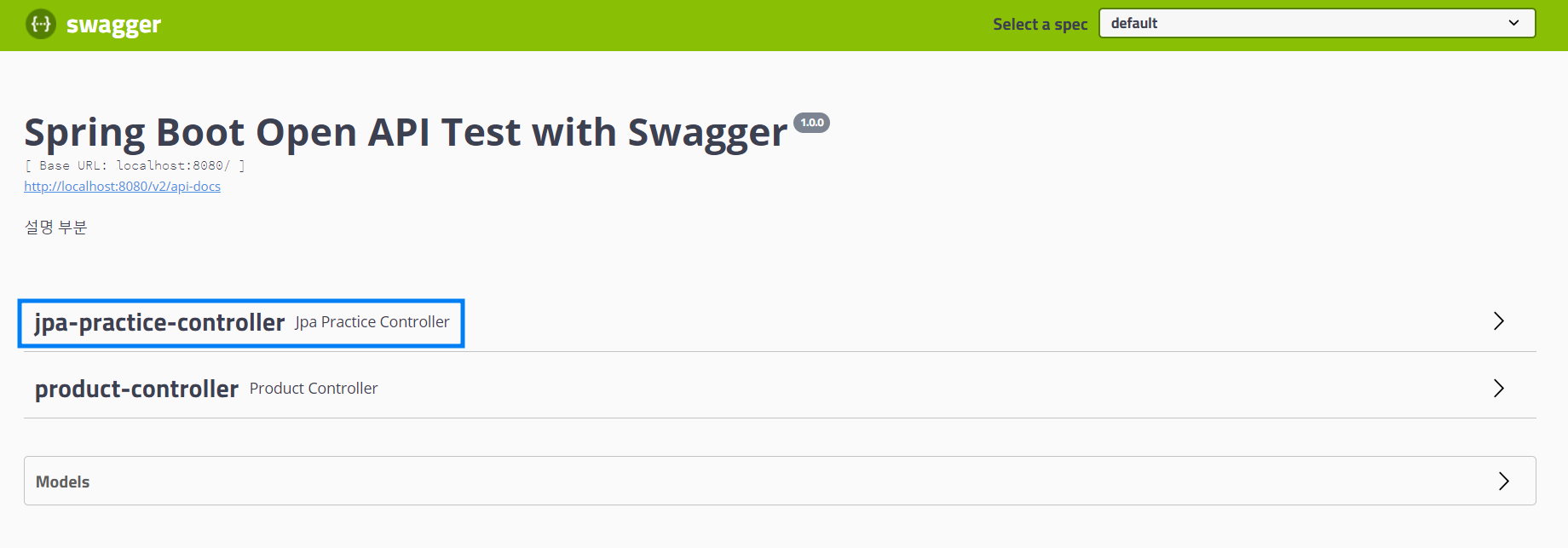
우선 예비 데이터를 넣기 위해 이전에 만들었던 product-controller의 POST 부에서 예비 데이터를 POST 해준다.
POST 된 데이터는 이전에 연결했던 mariaDB에 들어갔을 것이므로, HeidiSQL로 데이터가 잘 들어갔는지 확인한다.
필자가 넣은 예비 데이터들은 다음과 같다. 꼭 아래 쿼리문을 작성하고 쿼리 실행을 통해 데이터를 새로고침하길 바란다.

이제 다시 swagger에 돌아와 우리가 작성한 코드를 테스트해보자.



검색한 데이터가 잘 나오는 것을 볼 수 있다.
다른 메서드 역시 테스트해보자.
(+ delete 와 exists 메서드 또한 실습해본 결과 500 에러를 띄운다. 추후에 알아보고 구현 예정)
8.4 정렬과 페이징 처리
페이징 기법이란 인터넷 게시판 같은 곳에서 흔히 볼 수 있는, 페이지로 게시글을 몇 개 단위로 나누어 보여주는 기법이다.
앞서 살펴본 쿼리 메서드의 함수명명에서 추가로 정렬과 페이징 처리도 가능하지만, 다른 방법도 존재한다.
이번 장에서는 기본적인 정렬법과 페이징 처리 방법을 알아본다.
8.4.1 정렬 처리하기
첫 번째 방법은 메서드 명에 OrderBy를 명시하여 규칙에 맞게 작성하는 것이다.
order by 키워드는 sql 문에서 정렬 시에 활용되는 키워드로, Asc(오름차순), Desc(내림차순)과 함께 사용한다.
sql 문에서는 "ORDER BY 정렬 기준 칼럼명1 ASC, 정렬 기준 칼렴명2 DESC" 와 같은 방법으로 작성하는데
이를 메서드에 적용하는 규칙또한 동일하다.
OrderBy의 명시에서는 조건이 여러개더라도 사이에 AND 와 OR 구문을 적지 않는 것을 유의한다.
실습 코드를 작성해보자. 해당 코드는 name을 기준으로 하되, price는 내림차순으로, stock은 오름차순으로 정렬 조건을 정하여 출력하도록 하였다.

기존 코드로 출력하면 데이터베이스에 입력한 순서로 List를 반환할 뿐이었지만, 정렬 기준을 명시한 결과 기준에 따라 정렬 후 반환한 것을 알 수 있다.
단 이러한 방법은 메소드의 길이가 길어져 가동성이 저하될 수 있다.
따라서 이를 대체하는 방법으로 메서드의 매개변수에 Sort 객체를 전달하는 방법이 있다.
Sort 객체는 Sort.by() 형식으로 작성하며, 해당 메서드의 매개변수로 Order.asc/desc("정렬 기준 칼렴명")을 전달해준다.
위에서 실습한 정렬 방식과 동일한 결과를 내게끔, 해당 규칙으로 메서드를 작성하면 다음과 같다.


Repository에서 선언할 땐 단순히 파라메타에 Sort 객체를 명시하고,
실제 구현 시에는 Sort.by() 메서드 안에 Sort.Order.asc/desc("정렬 칼럼 명") 방식으로 사용한다.
이 역시 Sort.bry() 메서드가 길어지면 가독성이 좋지 않으므로,
Sort 객체를 반환하는 메서드를 따로 만들어서 해당 파라메타로 넘겨주는 방법도 존재한다.
8.4.2 페이징 처리
페이징이란 데이터베이스의 레코드를 개수로 나눠 페이지를 구분하는 방법이다.
흔히 커뮤니티에서 게시글을 몇 개 단위로 페이지로 넘겨 보는 방식을 많이 접했을 텐데, 그것을 편히 구현하는 객체이다.
사용 방법은 리턴 타입을 Page<>로 선언 및 메서드의 매개변수로 Pageable 객체를 넘겨주고,
실제 구현에서는 PageRequest.of() 메서드를 이용하여 페이지 번호 및 페이지에 몇 개의 데이터를 담을지, Sort 객체등의 정보를 명시해주면 된다.
작성 예시는 다음과 같다.


해당 방식은 첫 번째 매개변수에 "몇 번째 페이지부터(page : 0)"인지 명시하고,
"한 페이지에 몇 개의 데이터를 담을 것인지(size : 1)"를 명시하여 출력하도록 한 방식이다.

size가 1이기 때문에 하나의 객체만 페이지에 담기게 된다.
page.getContent()는 페이지에 담길 객체를 배열 형식으로 반환하며, 이것이 콘솔창으로 출력된 것을 확인할 수 있다.
8.5 @Query 어노테이션 사용하기
위에서의 실습처럼 데이터베이스의 값을 가져오는 방법으로는 메서드의 이름을 규칙에 맞게 선언하여 가져오는 방법과,
@Query 어노테이션을 활용한 JPQL 직접 작성 방법이 있다. JPQL을 사용하면 JPA 구현체에서 자동으로 쿼리 문장을 해석하고 실행한다. 주로 튜닝된 쿼리문의 사용 시에 작성한다.
앞에서 실습했던 findByName 기능의 경우, 같은 기능을 @Query 어노테이션을 활용하여 다음과 같이 작성 가능하다.

메서드명으로 기능을 명시했던 이전 실습과 달리, @Query 어노테이션을 사용했기 때문에 메서드명은 더이상 엄격한 규칙에 의해 작성할 필요성이 사라졌다.
query문은 대체적으로 sql 문과 유사한 규칙을 가지며, 중간의 AS는 생략 가능하다.
query문의 마지막 부분 "?1"은 1번째 매개변수를 의미하는데, 이는 간편하나 매개변수의 위치가 바뀔 경우 논리적 오류를 낳을 수 있다. 따라서 다음과 같이 수정 가능하다.

":[변수명]" 과 @Param("[변수명]")으로 둘을 이어주는 방식이며, 이는 가독성과 유지보수성을 증가시킨다.
8.6 QueryDSL 적용하기
앞서 살펴본 두 가지 방법은 편의성을 제공하는 좋은 방법이었지만, 문자열로 입력하기 때문에 컴파일 시점에 에러를 잡지 못하고 런타임 시점에 에러가 발생할 가능성이 있다.
이러한 문제를 해결하기 위해 사용되는 것이 QueryDSL이며, 이 방식은 문자열이 아닌 코드로 쿼리를 작성할 수 있게 한다.
8.6.1 QueryDSL이란?
QueryDSL은 정적 타입을 이용해 SQL과 같은 쿼리를 생성할 수 있도록 지원하는 프레임워크이다.
문자열 혹은 xml 대신 QueryDSL이 제공하는 플루언트(Fluent) API를 활용해 쿼리를 생성할 수 있다.
8.6.2 QueryDSL의 장점
QueryDSL의 장점은 다음과 같다.
- IDE가 제공하는 코드 자동 완성 기능을 활용할 수 있다.
- 문법적으로 잘못된 쿼리를 허용하지 않는다. 즉, 잘못된 쿼리라면 오류를 표기해준다.
- 동적인 쿼리 생성이 가능하다.
- 코드 작성이므로 가독성 및 생산성이 향상된다.
- 도메인 타입과 프로퍼티를 안전하게 참조할 수 있다.
8.6.3 QueryDSL을 사용하기 위한 프로젝트 설정
본격적으로 QueryDSL을 실습해보기 위하여 우선 pom.xml에 의존성을 추가하여야 한다.
다음 사진과 같이 dependencies 내부에 두 가지 dependency를 추가한다.

그리고 QueryDSL을 사용하기 위한 APT 플러그인을 추가하여야 한다.
이때 APT란 Annotation Processing Tool으로, 어노테이션으로 정의된 코드를 기반으로 새로운 코드를 생성하는 기능이다.
JDK 1.6 부터 도입되었으며, 클래스를 컴파일하는 기능도 제공한다.
이 역시 pom.xml 파일 내에서 진행하며, 하단의 <build> <plugins> 내부에 다음과 같이 작성한다.

<processor>com.querydsl.apt.jpa.JPAAnnotationProcessor</processor>해당 부분은 @Entity 어노테이션으로 정의된 엔티티 클래스를 찾아서 쿼리 타입을 생성한다.
설정이 끝났다면 좌측 상단의 maven에서 compile 단계를 클릭해 빌드 작업을 수행한다.
수행 방법은 다음과 같으며, 빌드가 완료되면 콘솔창에 다음과 같이 빌드 완료를 띄운다.


빌드가 완료되면 좌측의 프로젝트 목록에 다음과 같이 Q도메인 클래스가 생성된다.

QueryDSL은 지금까지 작성했던 엔티티 클래스와 Q도메인(Qdomain)이라는 쿼리 타입의 클래스를 자체적으로 생성하여 메타데이터로 사용하는데, 이를 통해 sql과 같은 쿼리를 생성하여 제공한다.
이때 해당 방법으로 Q도메인 클래스(QProduct) 파일이 생성되지 않았다면 다음과 같이 진행한다.
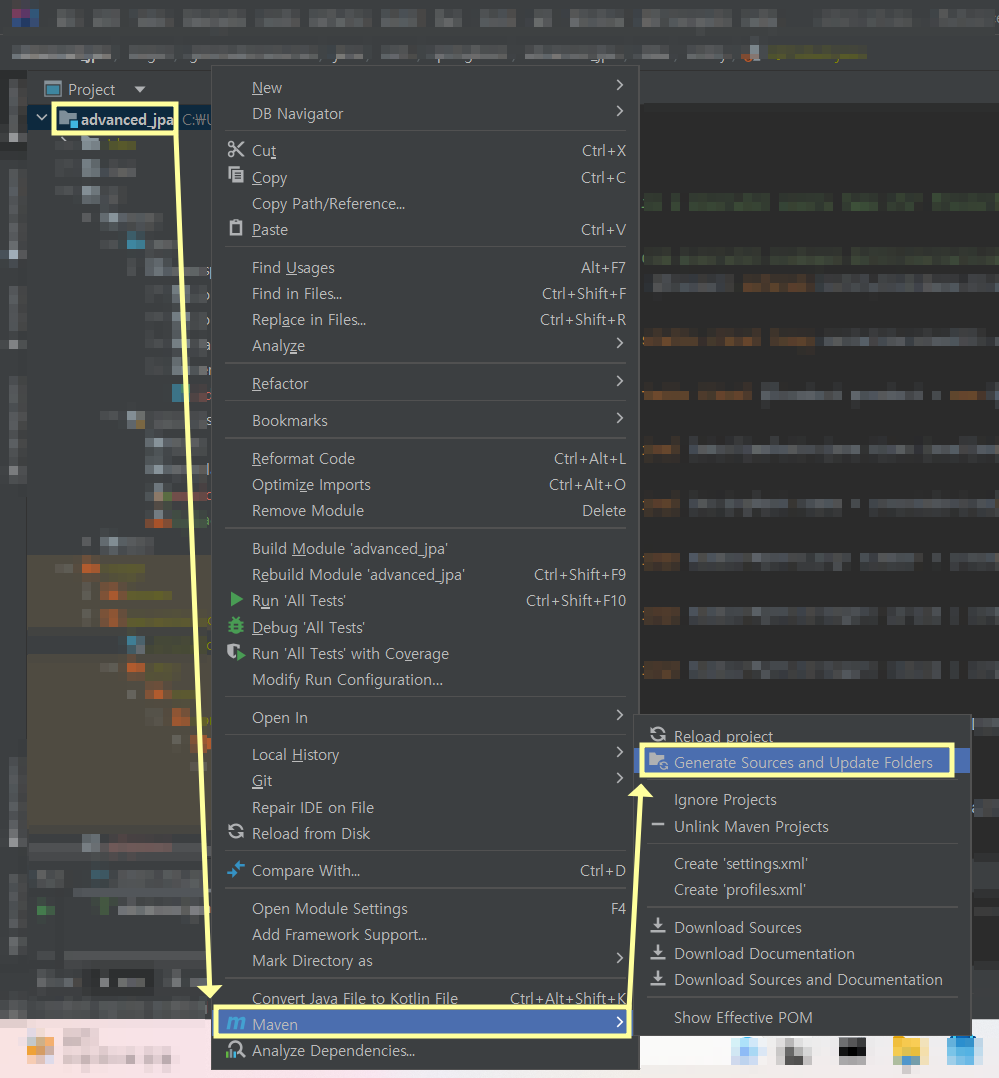
만약 코드가 정상적으로 동작하지 않는다면 다음과 같이 IDE 설정을 조정하여, IDE가 해당 파일을 소스 파일로 인식할 수 있도록 설정해준다.


8.6.4 기본적인 QueryDSL 사용하기
테스트 코드를 작성하여 실습을 진행해보자.
QueryDSL을 사용하는 방법은 아래와 같으며, 간단한 테스트를 위해 controller에서 작성하였다.

코드에서 볼 수 있듯이, JPAQuery<T> 클래스에 매개변수로 EntityManager 객체를 사용한 query 객체를 생성하여,
query.from() 메서드 매개변수로 QProduct 객체를 넣고 빌더 패턴으로 sql문을 유사하게 작성한다.
fetch() 메서드는 작성된 sql문의 결과를 list로 반환하는데 4.0.1 이전 버전의 QueryDSL이라면 list() 메서드를 사용한다.
List<T> fetch(), T fetchOne(), T fetchFirst(), Long fetchCount() 등의 메서드를 활용할 수 있다.
JPAQueryFactory 클래스를 활용하여 다음과 같이 작성할 수도 있다.

selectFrom은 "SELECT * FROM QProduct" 와 같으며, 둘을 다음과 같이 분리할 수도 있다.
List<Product> productList = factory.select(qProduct)
.from(qProduct)
.where(qProduct.name.eq("pencil"))
.orderBy(qProduct.price.asc())
.fetch();
select 할 대상 컬럼이 두 개 이상이라면 다음과 같이 com.querydsl.core.Tuple의 튜플을 리스트에 담아 사용할 수 있다.
List<Tuple> productList = factory.select(qProduct.name, qProduct.price)
.from(qProduct)
.where(qProduct.name.eq("pencil"))
.orderBy(qProduct.price.asc())
.fetch();
실제 비즈니스에서 QueryDSL을 활용하는 방법을 알아보자.
config 패키지에 QueryDSLConfiguration 클래스를 만들고, 다음과 같이 작성한다.

이렇게 query factory를 bean으로 등록 해놓는다면, 추후 사용하고자 하는 곳에선 JPAQueryFactory를 @Autowired 선언 하는 것만으로도 초기화 과정 없이 활용할 수 있게 된다.
8.6.5 QuerydslPredicateExecutor, QuerydslRepositorySupport 활용
QuerydslPredicateExecutor 인터페이스와 QuerydslRepositorySupport 클래스는 스프링 데이터 JPA가 제공하는 QueryDSL을 편하게 활용하는 방법이다.
우선 상속 방법은 간단하다. 기존 JpaRepository만 상속받던 repository에 함께 상속 받아준다.
public interface ProductRepository extends JpaRepository<Product, Long>, QuerydslPredicateExecutor<Product>
QuerydslPredicateExecutor 인터페이스는 기존 JpaRepository가 메서드의 매개변수로 String을 받아 해당 값을 데이터베이스에서 찾은 것과 달리, Predicate 객체를 대체하여 매개변수로 받는다. Predicate는 표현식을 작성할 수 있게 QueryDSL에서 제공하는 인터페이스이다.
이제 해당 repository를 활용하는 테스트 코드를 만들어보자. ProductRepository 내부에서 ctrl + shift + t 를 누르고 [OK] 로
ProductRepositoryTest 클래스를 만든다. 해당 테스트 클래스는 src/test/data/repository에 존재하게 된다.
클래스를 만들었다면 다음과 같이 작성한다.
package com.springboot.advanced_jpa.data.repository;
import com.querydsl.core.types.Predicate;
import com.springboot.advanced_jpa.data.entity.Product;
import com.springboot.advanced_jpa.data.entity.QProduct;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.Optional;
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class ProductRepositoryTest {
@Autowired
ProductRepository productRepository;
@Test
public void queryDSLTest(){
Predicate predicate = QProduct.product.name.containsIgnoreCase("소머리국밥");
Optional<Product> foundProduct = productRepository.findOne(predicate);
if(foundProduct.isPresent())
System.out.println(foundProduct.get());
QProduct qProduct = QProduct.product;
Iterable<Product> productIterable = productRepository.findAll(
qProduct.name.contains("pen")
.and(qProduct.price.between(0, 10000))
);
for(Product product : productIterable)
System.out.println(product);
}
}테스트 코드의 내용처럼 Predicate를 작성하여 repository 객체의 매서드에 전달할 수 있다.
메서드 별로 return 타입이 다르므로 유의해야 한다. 해당 코드에서는 findOne의 경우 하나의 객체만을 반환하기 때문에 데이터베이스에 하나만 존재하는 데이터에 대한 정보를 넣어주었으며 return 타입은 Optional이 되고, findAll의 경우 조건에 따라 여러 레코드를 반환할 수 있기 때문에 return 타입은 Iterable이 된다.
테스트를 실행하면 다음과 같이 잘 실행된다.

QuerydslRepositorySupport 추상 클래스 사용하기
- 해당 파트는 공부의 혼선을 피하기 위해 추후 spring이 더욱 숙달된 후 이해를 바탕으로 작성하겠다.
8.7 [ 한걸음 더 ] JPA Auditing 적용
JPA에서 'audit'이란 '감시하다'라는 의미를 가진다. 각 데이터마다 '누가', '언제' 데이터를 생성했고 변경했는지에 대한 정보는 공통적으로 들어가는 정보이며 필드로 관리된다. 흔히 생성/변경의 일자/주체에 대한 정보를 담는다.
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@ToString
@Entity
@Table(name = "product")
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long number;
@Column(nullable = false)
private String name;
@Column(nullable = false)
private Integer price;
@Column(nullable = false)
private Integer stock;
private LocalDateTime createdAt;
private LocalDateTime updatedAt;
}
기존 실습 코드를 다시 살펴보자. 해당 클래스는 엔티티 클래스이며 데이터베이스에 저장되는 필드들이 선언되어 있다.
하단부에 createdAt과 updatedAt은 생성, 수정일자에 대한 정보를 담으며, 우리의 기존 실습 코드는 해당 필드들에 대하여
데이터가 service 계층에서 save 혹은 update 될 때, 해당 필드를 LocalDateTime.now()로 직접 초기화하고 dao에 전달해주었었다.
@Override
public ProductResponseDto saveProduct(ProductDto productDto) {
Product product = new Product();
product.setName(productDto.getName());
product.setPrice(productDto.getPrice());
product.setStock(productDto.getStock());
product.setCreatedAt(LocalDateTime.now());
product.setUpdatedAt(LocalDateTime.now());
Product savedProduct = productDao.insertProduct(product);
ProductResponseDto productResponseDto = new ProductResponseDto();
productResponseDto.setNumber(product.getNumber());
productResponseDto.setName(product.getName());
productResponseDto.setPrice(product.getPrice());
productResponseDto.setStock(product.getStock());
return productResponseDto;
}
매번 이런 초기화를 통한 날짜 전달이 번거로우므로, Spring Data JPA는 이러한 부분을 해소하기 위해 자동으로 날짜 값을 넣어주는 기능을 제공한다.
8.7.1 JPA Auditing 기능 활성
auditing 기능을 활용하는 방법을 알아보자.
우선 main() 메서드가 있는 클래스에 @EnableJpaAuditing 어노테이션으로 기능을 활성화시킨다.
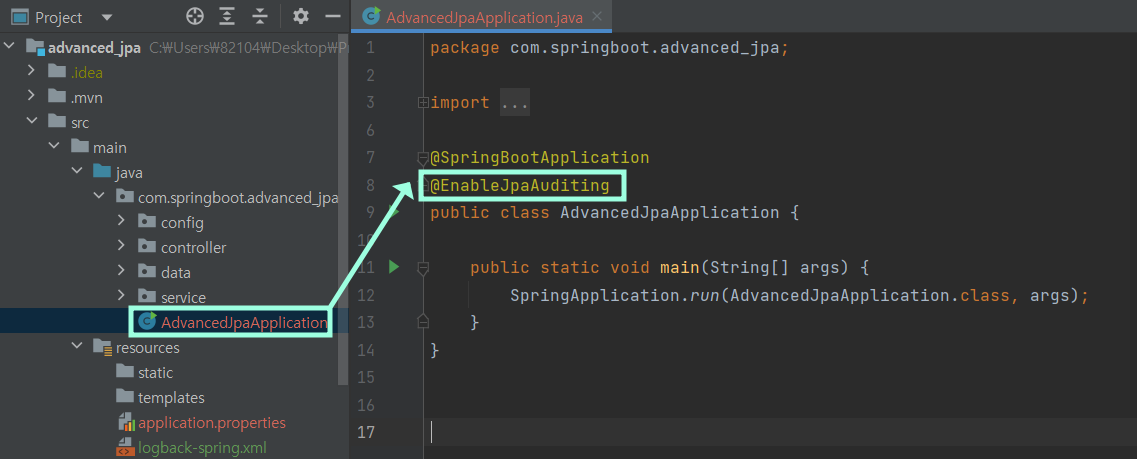
앞선 실습의 어노테이션 추가만으로 기능은 활성화되지만, 일부 @WebMvcTest로 테스트를 수행하는 코드 등에서 오류를 발생시킬 수 있다. 따라서 책에서 추천하는 방법은 별도의 configuration 클래스 생성을 통해 애플리케이션 클래스의 기능과 분리하여 활성화하는 방법이다. 해당 방법은 바로 다음 챕터에서 진행한다.
8.7.2 BaseEntity 만들기
configuration 클래스 생성을 통해 auditing 기능을 활용하는 방법을 실습해보자. 이때 해당 방법을 활용하려면
앞선 8.7.1 실습 과정에서 main() 클래스에 선언해둔 @EnableJpaAuditing 어노테이션을 지우고 진행하여야 정상적으로 동작한다.
코드의 중복을 없애기 위하여 각 엔티티에 공통으로 들어가게 되는 칼럼(필드)을 하나의 클래스로 빼서 생성한 엔티티 클래스를 base entity라 칭한다. (이는 자주 활용되는 기법이므로 숙지할 필요성이 있다) 생성 주체와 변경 주체는 활용할 일이 없으므로, 앞서 진행했던 createdAt, updatedAt 두 필드만 관리하는 것으로 base entity 실습을 진행한다.
data.entity 패키지에 BaseEntity 클래스를 생성하고 다음과 같이 작성한다.

사용된 어노테이션에 대한 설명은 다음과 같다.
- @MappedSuperclass : JPA의 엔티티 클래스가 상속받을 경우 자식 클래스에게 매핑 정보를 전달.
- @EntityListener : 엔티티를 데이터베이스에 적용하기 전후로 콜백을 요청할 수 있게 함.
- AuditingEntityListener : 엔티티의 Auditing 정보를 주입하는 JPA 엔티티 리스너 클래스.
- @CreatedDate : 데이터 생성 날짜를 자동으로 주입.
- @LastModifiedDate : 데이터 수정 날짜를 자동으로 주입.
이후 기존의 entity 클래스인 Product를 다음과 같이 수정한다.

call super 속성으로 부모 클래스의 필드를 포함하였고, 공통된 필드의 모음인 BaseEntity 클래스를 extends 하였다.
또한 이미 BaseEntity에서 구현된 createdAt, updatedAt 필드를 제거했다.
이제 해당 auditing 기능이 제대로 구현됐는지 확인해보자. 우선 날짜가 자동 주입되므로 service에서 createdAt, updatedAt 두 필드를 초기화하는 부분을 삭제해도 정상 작동 되어야 한다.

이후 서버를 실행하고 swagger을 통해 데이터를 입력, 이후 createdAt과 updatedAt이 올바른 시간으로 초기화되어 데이터베이스에 반영되었는지 확인해보자.
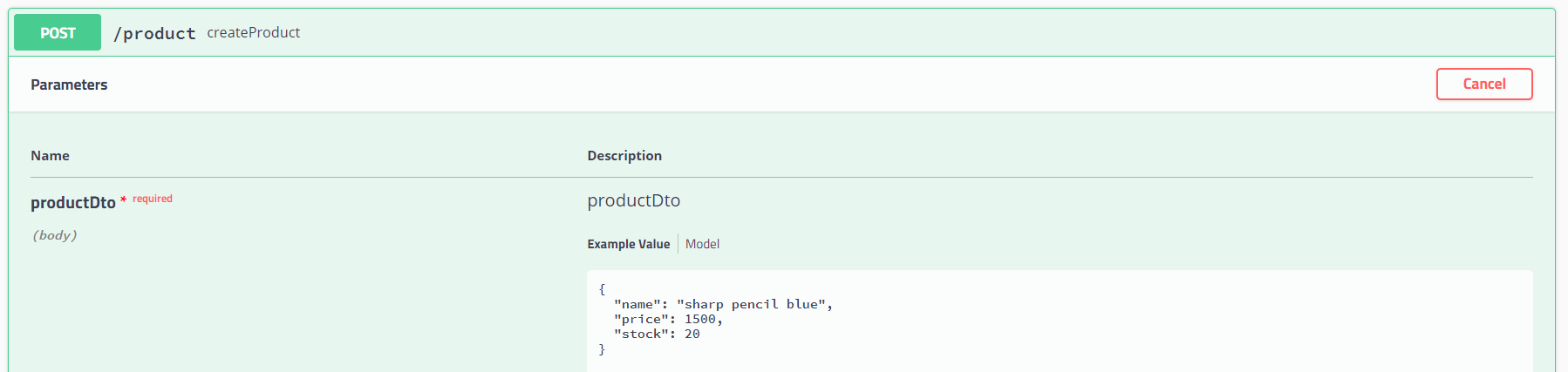

다음과 같이 날짜 필드가 잘 초기화되어 데이터베이스로 반영된 것을 확인할 수 있다.
8.8 정리
ORM의 개념과 자바의 표준 ORM 기술 스펙인 JPA를 살펴보았다.
'Backend > Spring' 카테고리의 다른 글
| [스프링 부트 핵심 가이드] 10. 유효성 검사와 예외 처리 (0) | 2023.06.21 |
|---|---|
| [스프링 부트 핵심 가이드] 09. 연관관계 매핑 (1) | 2023.06.14 |
| [스프링 부트 핵심 가이드] 07. 테스트 코드 작성하기 (0) | 2023.06.08 |
| [스프링 부트 핵심 가이드] 06. 데이터베이스 연동 (1) | 2023.06.01 |
| [스프링 부트 핵심 가이드] 05. API를 작성하는 다양한 방법 (0) | 2023.05.25 |



