
일단 씻고 나가자
[스프링 부트 핵심 가이드] 09. 연관관계 매핑 본문
(본 포스팅은 해당 도서의 정리 및 개인 공부의 목적 포스팅임을 밝힙니다.)
장정우, 『스프링 부트 핵심 가이드 : 스프링 부트를 활용한 애플리케이션 개발 실무』, 위키북스, 2022
09. 연관관계 매핑
RDBMS에서는 설계가 커지면 테이블을 도메인별로 구분하여 여러개로 나누고, join 등을 이용하여 연관관계를 설정한다.
JPA를 활용하는 애플리케이션도 마찬가지로 엔티티간의 연관관계를 표현할 수 있지만, 객체와 테이블의 성질이 다르기에 정확한 연관관례를 표현하기는 어렵다.
이번 장에서는 이러한 제약을 보완하며 연관관계를 매핑하고 사용하는 방법에 대해 알아보고 실습해본다.
9.1 연관관계 매핑 종류와 방향
두 엔티티 간 연관관계의 종류는 다음과 같다.
- 일대일 One To One (1:1)
- 일대다 One To Many (1:N)
- 다대일 Many To One (N:1)
- 다대다 Many To Many(N:M)
연관관계는 데이터베이스 관련 내용이므로 깊게 다루진 않지만, 간략히 알아보자.
연간관계란 두 엔티티 간의 연결 개수에 관한 정보이다. 책의 예시로 이해해본다.

그림과 같이 하나의 공급업체가 여러 종류의 물건을 공급해준다고 생각해보자.
물건/공급업체 두 가지로 구분한다고 생각했을 때, 물건은 상품 테이블로, 공급 업체는 공급 업체 테이블로 테이블을 분리할 수 있다.
상품 테이블의 정보엔 무엇이 들어갈까? 상품 번호, 상품 이름, 상품 가격 등의 정보가 개별 다른 상품에 대하여 저장된다.
공급 업체 테이블의 정보엔 무엇이 들어갈까? 공급 업체 번호, 업체 이름 등의 업체 자체의 정보가 저장될 것이다.
그렇다면 상품 테이블과 공급 업체 테이블의 관계는 어떻게 될까?
공급 업체 입장에서는 여러개의 상품을 공급 해줄 수 있기 때문에 공급 업체는 여러개의 공급 물건을 보유할 수 있으며,
이는 하나의 Supplier 엔티티는 여러 개의 Product 레코드와 연결될 수 있다는 것을 의미한다.
반대로 상품의 입장에서는 하나의 상품이 여러 개의 공급 업체를 가질 수는 없기 때문에
이는 하나의 Product는 단 하나의 Supplier만을 가질 수 있음을 의미한다.

즉, Product 테이블과 Supplier 테이블의 연관 관계는 업체는 하나(1), 상품은 여러개(N)이므로 다음과 같이 표현할 수 있다.

RDBMS에서는 이런 연간관계를 통해 외래키를 통하여 서로 참조하는 구조(양방향)로 만들어지지만,
JPA는 객체지향의 모델링이므로 엔티티 간 참조 방향의 설정(양방향/단방향)이 가능하다.
데이터베이스와 관계를 일치시키기 위해 양방향으로 설정해도 무관하지만, 비즈니스 로직의 관점에선 단방향만으로도 해결되는 경우가 많다.
- 양방향 : 각 엔티티가 서로의 엔티티를 참조
- 단방향 : 한쪽의 엔티티만 다른 한쪽을 참조
연관관계의 설정 후엔 한 테이블이 다른 테이블의 기본값을 외래키로 갖게 되는데, 외래키를 가진 테이블의 관계의 주인(Owner) 개념이 되며, 주인은 외래키를 사용할 수 있고 상대 엔티티는 읽는 작업만 수행할 수 있게 된다.
9.2 프로젝트 생성
이번 장의 실습을 위해 새로운 프로젝트를 생성한다.
start.spring.io에 접속하여 다음과 같이 설정하고 [GENERATE], 압축을 풀어 IDE로 open 한다.

역시 이전 장에서 작성한 클래스들을 가져와야 한다. 표기한 클래스들을 복사 후 올바른 위치에 붙여넣는다.
 |
 |
logback-spring 파일과 application.properties, pom.xml의 내용도 복사 붙여넣어야 한다.
크게 상관은 없지만 pom.xml의 프로젝트명이 아직 이전의 advanced_jpa로 되어 있기 때문에 해당 부분도 바꾸어준다.

그 외의 클래스들 역시 모든 클래스를 하나씩 들어가보며 import 경로 문제가 있는 부분을 모두 수정해주고,
QueryDSL을 위해 우측의 [Maven]에서 [complie] 빌드로 QBaseEntity, QProduct 파일도 생성해준다.
설정을 마쳤다면 RelationshipApplication 클래스의 main() 함수로 서버를 실행하여, 더이상 오류가 없는지 검토하자.
9.3 일대일 매핑
앞서 살펴본 연관관계를 토대로 엔티티를 매핑하는 실습을 진행해보자.
실습은 기존에 구현했던 Product 엔티티의 내용을 확장한 새로운 클래스를 생성하며, (실제 extends는 BaseEntity를 기준으로 함) 일대일 매핑될 두 테이블인 상품, 상품 정보 테이블의 정보는 다음과 같다.
| 상품 테이블 | |
| 상품 번호 | int |
| 상품 이름 | varchar |
| 상품 가격 | int |
| 상품 재고 | int |
| 공급 업체 번호 | int |
| 상품 분류 번호 | int |
| 상품 생성 일자 | DateTime |
| 상품 정보 변경 일자 | DateTime |
| 상품 정보 테이블 | |
| 상품 정보 번호 | int |
| 상품 설명 | varchar |
| 상품 번호 | int |
| 상품 정보 생성 일자 | DateTime |
| 상품 정보 변경 일자 | DateTime |
실습을 위해 두 개의 엔티티를 우선 일대일로 매핑해보도록 한다.
9.3.1 일대일 단방향 매핑
data.entity 패키지 내부에 ProductDetail 클래스를 생성하고 다음과 같이 작성한다.

@OneToOne 어노테이션을 통해 매핑(일대일)할 엔티티 객체를 설정한다. 즉, ProductDetail 클래스는 Product 클래스와 일대일 매핑 됨을 의미한다.
@JoinColumn 어노테이션은 name 뒤의 문자열에 해당하는 필드를 자동으로 만들어 매핑할 외래키를 설정해준다. 즉, product_number 이라는 필드를 만들어 Product 클래스의 PK와 매핑하는 필드로 사용한다. name으로 필드명을 명시하지 않아도 기본값으로 자동으로 매핑한다. @JoinColumn을 선언하지 않으면 엔티티를 매핑하는 중간 테이블이 생기며 관리 포인트가 늘어나기 때문에 좋지 않다. @JoinColumn은 name 외의 referencedColumnName(외래키가 참조할 상대 테이블의 칼럼명 지정), foreignKey(외래키를 생성하며 지정할 제약조건(unique, nullable, insertable, updatable 등)을 설정) 옵션 등을 활용할 수 있다.
이제 어플리케이션을 실행하면 hibernate가 자동으로 우리의 데이터베이스에 새로 생성된 entity 클래스를 테이블로 매핑하여 생성해준다. HeidiSQL로 확인한 새롭게 생성된 product_detail 테이블은 다음과 같다.

또한 새로운 실습을 위해 repository도 다음과 같이 새롭게 생성해준다.

이제 해당 기능이 정상적으로 작동하는지 테스트해보자.
새로운 클래스를 만들었으므로, 테스트 이전에 꼭 [Maven] -> [relationship] -> [Lifecycle] -> [compile] 을 더블클릭으로 빌드해주자.
ProductDetailRepository를 테스트하기 위해 [Ctrl + Shift + t]로 테스트 클래스를 만들고 다음과 같이 작성한다.
package com.springboot.relationship.data.repository;
import com.springboot.relationship.data.entity.Product;
import com.springboot.relationship.data.entity.ProductDetail;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class ProductDetailRepositoryTest {
@Autowired
ProductDetailRepository productDetailRepository;
@Autowired
ProductRepository productRepository;
@Test
public void saveAndReadTest() {
Product product = new Product();
product.setName("스프링 부트 JPA");
product.setPrice(5000);
product.setStock(500);
productRepository.save(product);
ProductDetail productDetail = new ProductDetail();
productDetail.setProduct(product);
productDetail.setDescription("스프링 부트와 JPA를 함께 볼 수 있는 책");
productDetailRepository.save(productDetail);
Product productTemp = productDetailRepository.findById(productDetail.getId()).get().getProduct();
ProductDetail productDetailTemp = productDetailRepository.findById(productDetail.getId()).get();
System.out.println();
System.out.println("<< product (Expected) >> " + "\n" + product + "\n");
System.out.println("<< product (Actual) >> " + "\n" + productTemp + "\n" + "\n");
System.out.println("<< product detail (Expected) >> " + "\n" + productDetail + "\n");
System.out.println("<< product detail (Actual) >> " + "\n" + productDetailTemp + "\n");
}
}해당 테스트의 진행은 이렇다.
테스트를 위한 임시 Product의 객체 product를 만들어 세팅하고, productRepository를 통해 PRODUCT 테이블에 넣는다.
역시 임시 ProductDetail 객체를 만드는데, setProuct를 통해 해당 객체와 product 객체를 일대일 매핑한 후 productDetailRepository를 통해 PRODUCT_DETAIL 테이블에 넣는다.
이후 productTemp 객체에는 이전에 생성했던 productDetail의 id로 실제 테이블에 해당 id를 가진 productDetail 객체를 가져와 (잘 반영되었는지 확인을 위해) getProduct()로 매핑되어 있는 product 객체를 담고,
productDetailTemp에는 앞선 과정에서 getProduct() 이전까지의 productDetail 객체를 담는다.
마지막으로 우리가 만들었던 객체와 데이터베이스를 거쳐 나온 객체가 동일한지를 콘솔을 통해 확인한다.
이때 assertEquals 등의 JUnit에서 제공하는 test 함수를 사용해도 되지만, 데이터베이스를 거치며 포맷화된 생성/수정 날짜의 변경 때문에 명확한 판단이 힘들므로 콘솔창을 통하여 확인하는 것이다.
결과는 다음과 같이, 포맷화된 날짜로 인한 차이를 제외하고는 같은 레코드를 성공적으로 불러왔다는 것을 확인할 수 있다.

로그(콘솔창)에 띄워진 실제 hibernate 코드를 보면 select 문에서 ProductDetail과 Product가 함께 조회되는 것을 볼 수 있는데, 이처럼 엔티티를 조회할 때 연관된 엔티티도 함께 조회되는 것을 '즉시 로딩'이라 한다. left outer join 문구를 통해 @OneToOne 어노테이션이 성공적으로 수행 됐음을 알 수 있다.
@OneToOne(optional = false) 속성으로 지정할 경우 inner join으로 바뀌게 된다.

이때 JOIN이란 무엇인지 간략하게 알아보자.
JOIN이란 두 테이블을 연결시킬 때 설정하는 규칙의 일종으로,
가장 많이 쓰이는 JOIN에는 LEFT/RIGHT (OUTER) JOIN, INNER JOIN이 있다. 둘에 대해 알아보자.
쉬운 설명을 위해 다음 그림과 같이 A, B 테이블이 있다고 가정한다.

- LEFT/RIGHT (OUTER) JOIN
LEFT와 RIGHT의 차이는 단지 방향의 차이이며, 기준이 되는 테이블을 무엇으로 설정할 것인지에 대한 차이일 뿐이다.
"A LEFT JOIN B ON A.컬럼 = B.컬럼" 처럼 쿼리문을 작성하며, 이는 "B RIGHT JOIN A ON B.컬럼 = A.컬럼" 과 같다.
즉, LEFT JOIN은 말 그대로 '왼쪽' 을 기준으로 JOIN 하는 것을 의미한다. 왼쪽에 존재하는 데이터라면, JOIN되는 다른 컬럼을 NULL로 두고서라도 무조건 만들겠다는 의미이다.
예시에서 "A a LEFT JOIN B b ON a.id = b.id" 의 쿼리를 실행하면 어떻게 될까?
우선 조건문이 a.id = b.id 이므로 a의 id와 b의 id 값이 같은 것끼리 매치될 것이다. (1, a, 100) (2, b, 200) 에 대해서는 같은 값이 있으니 성공적으로 만들어질 텐데, 그렇다면 B 테이블에 없는 3번 id에 대해서는 레코드가 만들어질까?

결과는 만들어진다. LEFT JOIN이므로 A가 기준이고, 그 의미는 앞서 설명했듯 A가 기준이 되니 A의 데이터는 모두 살려서 테이블을 만들겠다는 의미이다. 하지만 B 테이블에서는 3번 id가 존재하지 않았으니, 해당 컬럼은 null인 상태로 형성된다.
- INNER JOIN
INNER의 경우 방향이 없다. 이유는 '교집합'의 의미이므로, 기준점의 의미가 없기 때문이다.
앞서 OUTER의 경우를 보았으니 INNER에 대한 이해는 쉬울 것이다. 앞선 두 테이블을 INNER JOIN하면 어떻게 될까?

교집합이기 때문에 3번 id에 대한 레코드는 만들어지지 않음을 확인할 수 있다.
9.3.2 일대일 양방향 매핑
이전 실습에서 단방향으로 매핑된 엔티티들을 양방향으로 바꾸는 실습을 진행해보자.
객체에선 양방향이 단지 서로 단방향을 가지고 있음을 의미한다. 따라서 Product 엔티티에도 ProductDetail을 매핑해준다.

당연히 Product의 테이블에도 product_detail 컬럼이 생기게 된다.
단, 이 경우 양쪽에서 외래키를 들고 있기 때문에 left outer join이 두 번이나 수행되어 효율성이 떨어진다.
따라서 한쪽의 테이블에서만 외래키를 바꿀 수 있도록 정하는 것이 좋다. 엔티티는 양방향으로 매핑하되, 한쪽에게만 외래키를 주는 방법이 mappedBy 속성이다.

mappedBy의 "product" 값은 연관관계의 상대 엔티티의 필드명이다. 즉, ProductDetail의 product 필드를 명시한 셈이다.
이렇게 처리한 경우 Product 테이블의 product_detail 컬럼은 사라지게 되고, 현재 Product 객체는 ProductDetail 객체가 주인이 된 것이다.
mappedBy는 상대방에게 외래키를 주는 기능이므로, 다대일 관계에선 '다(Many)' 쪽에 존재해야 한다.
하지만 양방향 참조로 인해 toString의 실행 시 양쪽이 서로를 참조하여 출력하는 '순환 참조' 현상으로 stackOverflowError가 유발된다. 따라서 웬만하면 단방향을 사용하되, 양방향 설정이 필요한 경우엔 다음과 같이 toString을 exclude 시키는 것이 필요하다.

9.4 다대일, 일대다 매핑
다시 돌아가서, 원래의 논리성에 맞게 상품 테이블과 공급 업체 테이블을 1:N 관계로 매핑하는 법에 대해 살펴본다.
9.4.1 다대일 단방향 매핑
우선 공급 업체 테이블 생성을 위해 Provider 엔티티 클래스를 다음과 같이 작성한다.

해당 클래스는 공급 업체를 의미하는 엔티티 클래스이며, 간단한 실습을 위해 필드는 id와 name 만으로 구성한다.
공급 업체와의 관계를 위해 Product 클래스도 다음과 같이 수정해준다.

Product가 Provider 객체를 외래키로 가지고 있기 때문에 Product가 Provider의 주인이며, @ManyToOne을 통해 Product와 Provider의 관계가 N:1임을 명시하고 있다. @JoinColumn을 통해 Product의 테이블에 "provider_id"이라는 컬럼을 만들어 Provider의 PK 값을 가져와 관리할 것이다.
또한 이후의 실습을 위해 Provider 엔티티를 활용하기 위한 ProviderRepository도 생성해준다.

이제 테스트를 진행해보자.
테스트의 편의성을 위해 Product와 Provider 클래스에 @AllArgsConstructor, @Builder 어노테이션을 추가하고 진행함을 알아두길 바란다.
테스트는 다음과 같이 작성한다.
package com.springboot.relationship.data.repository;
import com.springboot.relationship.data.entity.Product;
import com.springboot.relationship.data.entity.Provider;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class ProviderRepositoryTest {
@Autowired
ProductRepository productRepository;
@Autowired
ProviderRepository providerRepository;
@Test
void relationshipTest() {
Provider provider = Provider.builder()
.name("ㅇㅇ물산")
.build();
providerRepository.save(provider);
Product product = Product.builder()
.name("가위")
.price(5000)
.stock(500)
.provider(provider)
.build();
productRepository.save(product);
Product productTemp = productRepository.findById(1L).orElseThrow(RuntimeException::new);
Provider providerTemp = productRepository.findById(1L).orElseThrow(RuntimeException::new).getProvider();
System.out.println("\n<< product >>");
System.out.println(productTemp + "\n");
System.out.println("<< provider >>");
System.out.println(providerTemp + "\n");
}
}테스트의 흐름은 다음과 같다.
Provier 객체를 먼저 생성하고, Product 객체인 product에 provider 객체를 매핑한다. 각각의 객체를 각각의 repository에 저장하고, 이후 productTemp에는 product 객체가 잘 담겼는지 데이터베이스에서 id를 통해 가져와서 담고, providerTemp에는 id를 통해 가져온 productTemp 객체에 provider이 잘 매핑이 되었는지 확인을 위해 담는다. 이후 두 객체의 정보를 출력한다.

결과는 다음과 같이 우리가 만든 객체가 잘 전달되었고, 해당 product 객체에 provider 객체가 잘 매핑됨이 나타난다.
9.4.2 다대일 양방향 매핑
이제 공급업체를 통해 등록된 상품을 조회하기 위한 일대다 연관관계를 설정한다.
우리는 앞서 Product 클래스에서 Provider을 @ManyToOne으로 설정했으므로,
이번에는 Provider 클래스에서 Product를 @OneToMany 설정해준다면 일대다 및 양방향 매핑이 이루어진다.
일다대이므로 여러 엔티티를 한 곳에 저장하기 위한 자료구조 List를 활용한다.
다음과 같이 Provider 클래스를 추가 작성한다.

mappedBy는 연관관계에 있는 Product 클래스의 provier 필드에만 외래키를 주는 방식이다. 역시 순환 참조를 방지하기 위해 @ToString.Exclude를 사용했다.
fetch와 FetchType.EAGER이란 무엇일까? 간단히 알아보자.
fetch는 흔히 '게임 패치, 어플리케이션 패치' 등에서 사용하는 '패치'와 같은 단어이다.
패치에는 EAGER, LAZY 두 가지가 있는데, 단어의 뜻대로 eager(즉시, 열렬한)/lazy(지연, 게으른) 두 의미의 로딩 방식이며, 이는 어떤 엔티티 객체를 불러올 때 연관된 객체를 함께(eager) 불러올 것이냐, 아니면 필요한 부분만(lazy) 불러올 것이냐의 차이가 있다.
우리의 실습 코드에서 해당 의미를 알아보자.
만약 우리가 앞서 Provider 의 코드를 추가하고, DB에서 Provider 객체를 요청하면 어떻게 될까?

그림과 같이 Provider -> Product -> ProductDetail이 차례로 연관되어 있으므로 세 클래스에 대한 정보를 모두 가져온다.
이렇게 세 클래스의 정보를 모두 불러온다는 의미는 쿼리문(JOIN)을 세 개 날리는 것과 같으므로 (JPQL의 N+1 문제), 결국 그만큼의 부하와 자원 및 시간 손해를 의미하게 된다. 이는 데이터가 많아질수록 더 심각한 문제를 야기한다.
이런 문제를 해결하기 위해선 어떤 아이디어가 필요할까?
바로 "당장 사용하지 않는 부분은 불러오지 않고 필요할 때만 DB에서 조회하는" 전략이 필요하다.
만약 DB에서 Provider 객체만의 정보가 필요한 상황(ex. 공급 업체의 이름만이 필요한 상황)이라면, 연관된 Product에 대해서는 해당 로직에선 필요하지 않기에 당장 해당 정보를 로딩하여 쿼리를 날릴 필요는 없으므로 프록시(가짜, 껍데기) 객체만을 전달한 후 나중에 Product의 진짜 정보가 필요하게 될 때 따로 쿼리를 날려 조회하면 되겠다.
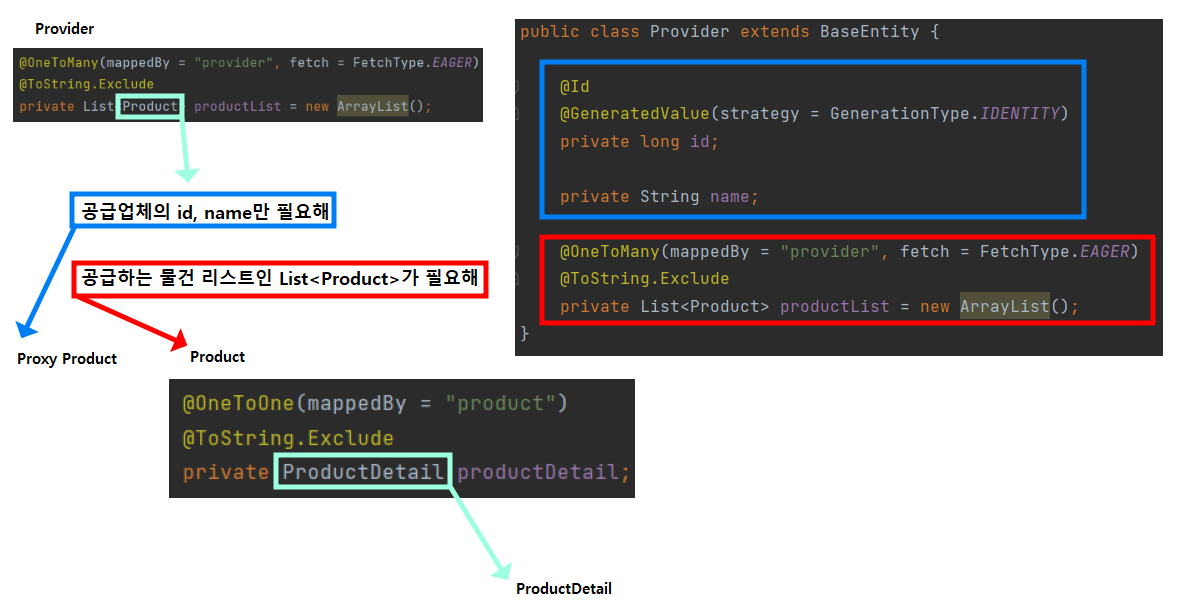
이렇게 어떤 정보의 조회 시 "모든 정보"를 한 번에 불러오는 전략이 "eager (FetchType.EAGER)" 이며,
요청 요청마다 프록시 객체를 이용하여 "필요한 정보만" 불러오는 전략이 "lazy (FetchType.LAZY)" 이다.
실무에서는 무조건적으로 LAZY 전략을 채택하지만,
만일 lazy로 데이터베이스에서 가져온 객체에 대하여 바로 프록시 객체에 접근할 경우 No Session 에러(데이터 베이스와의 연결이 필요함)를 내므로 @Transactional 등의 어노테이션을 걸어주어야 한다.
우리는 간단한 실습을 진행할 것이므로 No Session 에러 방지를 위해 eager로 데이터를 불러오도록 설정한다.
참고 사이트
https://youtube.com/watch?v=CghP7yW21Nw&feature=share7
이제 ProductList가 잘 반영되었는지 확인할 수 있는 테스트 코드를 다음과 같이 작성해본다.
package com.springboot.relationship.data.repository;
import com.springboot.relationship.data.entity.Product;
import com.springboot.relationship.data.entity.Provider;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class ProviderRepositoryTest {
@Autowired
ProductRepository productRepository;
@Autowired
ProviderRepository providerRepository;
@Test
void relationshipTest() {
Provider provider = Provider.builder()
.name("ㅇㅇ상사")
.build();
providerRepository.save(provider);
Product product1 = Product.builder()
.name("펜")
.price(2000)
.stock(100)
.provider(provider)
.build();
productRepository.save(product1);
Product product2 = Product.builder()
.name("가방")
.price(20000)
.stock(200)
.provider(provider)
.build();
productRepository.save(product2);
Product product3 = Product.builder()
.name("노트")
.price(3000)
.stock(1000)
.provider(provider)
.build();
productRepository.save(product3);
List<Product> products = providerRepository.findById(provider.getId()).get().getProductList();
for(Product product : products)
System.out.println(product);
// 연관관계 주인 테스트
Product product4 = Product.builder()
.name("연필")
.price(500)
.stock(10)
.provider(provider)
.build();
providerRepository.findById(provider.getId()).get().getProductList().add(product4);
List<Product> products2 = providerRepository.findById(provider.getId()).get().getProductList();
for(Product product : products2)
System.out.println(product);
}
}
결과는 콘솔창에 다음과 같이 두 번이 출력된다.

마지막에 product4를 productList에 add 했는데도, 두 번째의 결과 역시 product4는 반영되지 않은 결과가 나온 이유는
Provider 엔티티는 Product와의 관계에서 연관관계의 주인이 아니기 때문에 데이터베이스에 반영되지 않는 것이다.
9.4.3 일대다 단방향 매핑
이번 실습에서는 일대다 단방향 매핑법을 진행한다.
실습을 위해 Category(상품 분류)라는 새로운 엔티티 클래스를 다음과 같이 생성 및 작성한다.
| 상품 분류 테이블 | |
| 상품 분류 번호 | int |
| 상품 분류 코드 | varchar |
| 상품 분류 이름 | varchar |

JoinColumn을 통해 Product 클래스가 필드를 명시하지 않아도 Product 클래스에 catery_id라는 컬럼을 생성해준다.

참고 사이트
https://boomrabbit.tistory.com/217
테스트 실습을 위해 CategoryRepository를 다음과 같이 작성하고, 그에 맞는 테스트 클래스도 다음과 같이 작성한다.
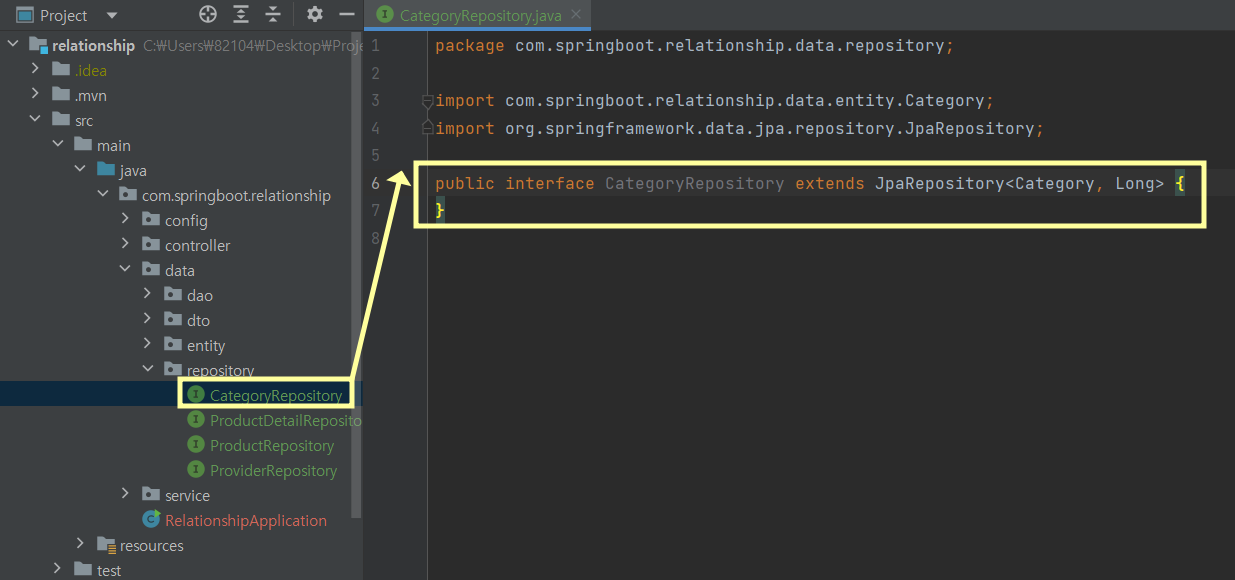
package com.springboot.relationship.data.repository;
import com.springboot.relationship.data.entity.Category;
import com.springboot.relationship.data.entity.Product;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class CategoryRepositoryTest {
@Autowired
ProductRepository productRepository;
@Autowired
CategoryRepository categoryRepository;
@Test
void relationshipTest() {
// given
Product product = Product.builder()
.name("펜")
.price(2000)
.stock(100)
.build();
productRepository.save(product);
Category category = new Category();
category.setCode("S1");
category.setName("문구");
category.getProducts().add(product);
categoryRepository.save(category);
// when
List<Product> products = categoryRepository.findById(1L).get().getProducts();
// then
System.out.println("\n<< expected >>\n" + product);
System.out.println("\n<< actual >> \n");
for(Product p : products)
System.out.println(p);
System.out.println();
}
}
일대다 연관관계에서는 연관관계 설정을 위한 update 쿼리가 발생한다.
이런 문제를 해결하기 위해선 일대다 양방향 보다는 다대일 연관관계가 추천된다.

9.5 다대다 매핑
다대다 연관관계는 실무에서는 거의 사용되지 않는 구성이다.
이러한 관계에선 각 엔티티가 서로의 리스트를 가지는 구조로 이루어지는데, 이런 경우엔 교차 엔티티라는 중간 테이블을 생성하여 다대다를 일대다 혹은 다대일 관계로 해소한다.
9.5.1 다대다 단방향 매핑
실습을 위해 Producer(생산 업체)라는 새로운 엔티티 클래스를 다음과 같이 생성 및 작성한다.
생산 업체 엔티티는 Product 엔티티와 다대다 관계이며, 한 종류의 상품이 여러 생산업체를 통해 생산되기도 하고, 생산업체 한 곳이 여러 상품을 생산할 수도 있다는 논리로 설정한다.
| 생산 업체 테이블 | |
| 생산업체 번호 | int |
| 생산업체 코드 | varchar |
| 생산업체 이름 | varchar |

@ManyToMany 어노테이션을 통해 다대다 연관관계를 설정했으며, 리스트를 필드로 가지는 객체에서는 외래키를 가지지 않기 때문에 @JoinColumn은 설정하지 않아도 된다.
@JoinTable은 앞서 얘기한 교차 엔티티에 대한 설정으로, name 속성을 통해 새롭게 생성되는 교차 엔티티의 이름을 명명할 수 있다. 설정한 "producer_product"는 해당 설정이 없을 때 디폴트로 설정되는 테이블 명과 동일하다.
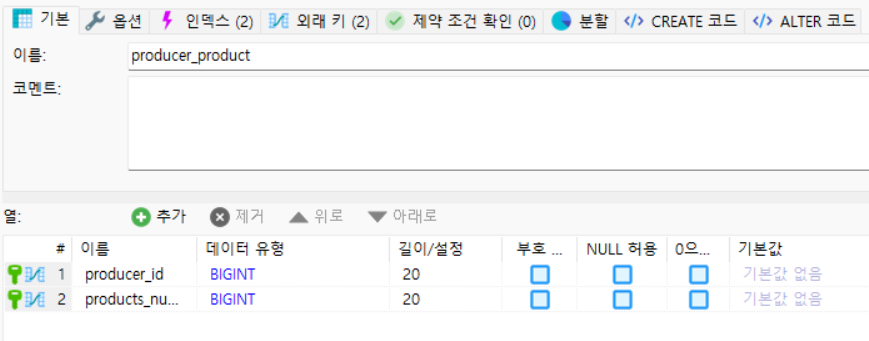
그림과 같이 producer_product 테이블은 두 개의 외래키로 존재하며, Producer과 Product 엔티티(클래스)의 PK를 각각 가져와 컬럼으로 사용하고 있는 것을 볼 수 있다.
연관관계 테스트를 위해 다음과 같이 리포지토리를 생성하고 테스트 코드를 작성한다.

package com.springboot.relationship.data.repository;
import com.springboot.relationship.data.entity.Producer;
import com.springboot.relationship.data.entity.Product;
import org.assertj.core.util.Lists;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.transaction.annotation.Transactional;
import static org.junit.jupiter.api.Assertions.*;
@SpringBootTest
class ProducerRepositoryTest {
@Autowired
ProductRepository productRepository;
@Autowired
ProducerRepository producerRepository;
@Test
@Transactional
void relationshipTest() {
Product product1 = saveProduct("동글펜", 500, 1000);
Product product2 = saveProduct("네모 공책", 100, 2000);
Product product3 = saveProduct("지우개", 152, 1234);
Producer producer1 = saveProducer("flature");
Producer producer2 = saveProducer("wikibooks");
producer1.addProduct(product1);
producer1.addProduct(product2);
producer2.addProduct(product2);
producer2.addProduct(product3);
producerRepository.saveAll(Lists.newArrayList(producer1, producer2));
System.out.println();
producerRepository.findById(1L).get().getProducts().stream().forEach(System.out::println);
System.out.println();
}
private Product saveProduct(String name, Integer price, Integer stock) {
Product product = new Product();
product.setName(name);
product.setPrice(price);
product.setStock(stock);
return productRepository.save(product);
}
private Producer saveProducer(String name) {
Producer producer = new Producer();
producer.setName(name);
return producerRepository.save(producer);
}
}가독성을 위해 메서드를 분리하는 부분에서 트랜잭션이 끊어져 No Session 에러를 발생시킬 수 있으므로 @Transactional을 통해 해당 에러를 방지했다.
이때 Lists.newArrayList()는 매개변수를 담은 새로운 리스트를 생성하는 것으로, new ArrayList()와 다르지 않다. (제너릭을 생략하는 이점이 있다.)
결과는 다음과 같이 나온다.

이 결과는 producer1, producer2를 담은 리스트를 출력하는 것으로, 해당 객체들이 제대로 데이터베이스에 매핑이 되어 있는지 확인하려면 데이터베이스의 앞선 교차 엔티티인 producer_product 테이블을 확인하여야 한다. 해당 테이블을 확인하면 각 외래키끼리 잘 엮여 있는 것을 볼 수 있다.
9.5.2 다대다 양방향 매핑
다대다 양방향 매핑은 단방향과 다르지 않다. 9.5.1에서 Producer 클래스 쪽에 작성한대로 Product 클래스 쪽에 동일하게 작성하면 된다. 다음과 같이 Product 클래스에 내용을 추가해준다.

확인을 위해 테스트 코드를 작성한다. 테스트 코드는 9.5.1에서 작성한 테스트 코드에 이어 적는다. 다음과 같이 작성하며, 결과 역시 다음과 같이 나온다.

9.6 영속성 전이
영속성 전이(cascade)란 특정 엔티티의 영속성 상태를 변경할 때 해당 엔티티와 연관된 엔티티의 영속성 상태도 변경하는 것을 의미한다. 즉, 어떤 엔티티가 영속 상태의 변경이 일어나면 매핑으로 연관된 엔티티도 동일한 동작이 일어나도록 하는 것이다.
이때 다시 한번 영속성 컨텍스트에 대해 리마인드하자면, 영속성 컨텍스트는 애플리케이션과 데이터베이스 사이에서 객체를 보관하는 가상의 DB 역할을 한다. 이렇게 중간 단계를 두는 것으로 1차 캐시, 지연 로딩 등의 이점을 얻을 수 있다.
참고 사이트
https://code-lab1.tistory.com/290
cascade는 연관 관계를 설정하는 어노테이션에서 소괄호 안의 속성으로 활용할 수 있다.
cascade 타입의 종류는 다음과 같다.
- ALL : 모든 영속 상태 변경에 대해 영속성 전이를 적용
- PERSIST : 엔티티가 영속화할 때 연관된 엔티티도 함께 영속화
- MERGE : 엔티티를 영속성 컨텍스트에 병합할 때 연관된 엔티티도 병합
- REMOVE : 엔티티를 제거할 때 연관된 엔티티도 제거
- REFRESH : 엔티티를 새로고침할 때 연관된 엔티티도 새로고침
- DETACH : 엔티티를 영속성 컨텍스트에서 제외하면 연관된 엔티티도 제외
9.6.1 영속성 전이 적용
상품 엔티티와 공급업체 엔티티에 영속성 전이를 적용하는 실습을 진행해보자.
논리 흐름은, 특정 가게가 새로운 공급업체와 계약하며 몇 가지 새 상품을 입고시키는 상황을 가정한다.
따라서 Provider 클래스를 다음과 같이 수정한다.

테스트를 위해 이전에 작성했던 ProviderRepositoryTest 클래스에 다음과 같이 추가로 작성한다.
@Test
void cascadeTest() {
Provider provider = savedProvider("새로운 공급업체");
Product product1 = savedProduct("상품1", 1000, 1000);
Product product2 = savedProduct("상품2", 500, 1500);
Product product3 = savedProduct("상품3", 750, 500);
product1.setProvider(provider);
product2.setProvider(provider);
product3.setProvider(provider);
provider.getProductList().addAll(Lists.newArrayList(product1, product2, product3));
providerRepository.save(provider);
}
private Provider savedProvider(String name) {
Provider provider = new Provider();
provider.setName(name);
return provider;
}
private Product savedProduct(String name, Integer price, Integer stock) {
Product product = new Product();
product.setName(name);
product.setPrice(price);
product.setStock(stock);
return product;
}위의 테스트 코드에서 각 product 객체들은 초기화만 된 상태이며, productRepository에 저장하지 않으므로 영속성 컨텍스트에 담기지 않는다. 영속성 컨텍스트에 담기는 객체는 providerRepository에 save() 되는 provider 뿐인데, 이 provider 객체는 3개의 product 객체를 모두 productList에 담은 상태로 영속성 컨텍스트에 담기게 된다.
따라서 provider가 가지고 있던 product 객체가 영속성 컨텍스트에 담기는지에 대한 것을 확인해보자.
우선 테스트 실행 후 콘솔창에 출력되는 hibernate sql 쿼리이다.
다음과 같이 save() 했던 provider 객체 뿐 아니라 함께 담았던 product 3 객체 또한 함께 담긴 것을 볼 수 있다.

HeidiSQL을 통해 테이블을 확인해보자. 다음 사진은 테이블에 저장된 provider 객체와, 해당 provider id를 외래키로 가지고 있는 product의 3객체를 보이고 있다.


그렇다면 cascade에 대한 속성을 없애고 테스트를 진행하면 어떻게 될까? 다음과 같이 save()로 명시했던 provider 객체만 데이터베이스에 반영하는 hibernate 쿼리를 확인할 수 있다.

다만 이러한 영속성 전이는 주의해서 사용하여야 한다. 예를 들어 REMOVE 혹은 ALL 같은 속성에서는 특정 엔티티의 삭제 시 연관된 모든 엔티티가 모두 삭제되므로, 사이드 이펙트(side effect)를 고려한 사용이 요구된다.
9.6.2 고아 객체
JPA의 고아(orphan) 객체란 부모 엔티티와 연관관계가 끊어진 엔티티를 의미한다.
JPA는 이러한 고아 객체를 자동으로 삭제하는 기능을 제공하며, 이러한 기능은 만일 삭제하려는 엔티티가 또 다른 엔티티와 연관이 되어 있다면 삭제 되지 않아야 하므로 주의를 요한다.
해당 기능을 실습해보자. 앞서 cascade를 작성했던 provider 클래스에 orphanRemoval 속성을 다음과 같이 추가한다.

테스트를 위해 이전에 작성했던 ProviderRepositoryTest 클래스에 다음과 같이 추가로 작성한다.
@Test
@Transactional
void orphanRemovalTest() {
Provider provider = savedProvider("새로운 공급업체");
Product product1 = savedProduct("상품1", 1000, 1000);
Product product2 = savedProduct("상품2", 500, 1500);
Product product3 = savedProduct("상품3", 750, 500);
product1.setProvider(provider);
product2.setProvider(provider);
product3.setProvider(provider);
provider.getProductList().addAll(Lists.newArrayList(product1, product2, product3));
providerRepository.saveAndFlush(provider);
System.out.println("\n<< save >>");
providerRepository.findAll().forEach(System.out::println);
productRepository.findAll().forEach(System.out::println);
System.out.println();
Provider foundProvider = providerRepository.findById(1L).get();
foundProvider.getProductList().remove(0);
System.out.println("\n << delete >>");
providerRepository.findAll().forEach(System.out::println);
productRepository.findAll().forEach(System.out::println);
System.out.println();
}테스트의 흐름은 Product 객체 3개를 만들고 provider에 연결한 후, saveAndFlush로 먼저 데이터베이스에 반영한다.
이후 반영된 결과를 콘솔에 출력하고, provider의 productList에서 0번 product 즉, product1 을 remove() 했을 때 데이터베이스에 product1이 삭제 되는지를 확인한다.
provider가 product1을 삭제했다면 product1은 연관관계를 잃기 때문에 orphanRemoval에 의해 데이터베이스에서까지 삭제되어야 하기 때문이다.
결과는 다음과 같다.


연관관계가 끊긴 product1 객체가 데이터베이스에서 제거된 것을 볼 수 있다. hibernate는 연관관계의 제거 시 상태 감지를 통해 삭제 쿼리를 수행한다.
9.7 정리
연관관계와 영속성 전이 개념을 살펴보았다.
추가로 Spring Data JPA를 활용하여 hibernate를 활용하는 것이 아닌,
hibernate만을 활용한 JPA 자체를 사용하는 것을 함께 공부하면 DAO와 리포지토리의 개념 차이 등의 스프링 부트 JPA에 대한 폭 넓은 이해가 가능해질 것이다.
'Backend > Spring' 카테고리의 다른 글
| [스프링 부트 핵심 가이드] 11. 액추에이터 활용하기 (0) | 2023.06.27 |
|---|---|
| [스프링 부트 핵심 가이드] 10. 유효성 검사와 예외 처리 (0) | 2023.06.21 |
| [스프링 부트 핵심 가이드] 08. Spring Data JPA 활용 (0) | 2023.06.08 |
| [스프링 부트 핵심 가이드] 07. 테스트 코드 작성하기 (0) | 2023.06.08 |
| [스프링 부트 핵심 가이드] 06. 데이터베이스 연동 (1) | 2023.06.01 |



